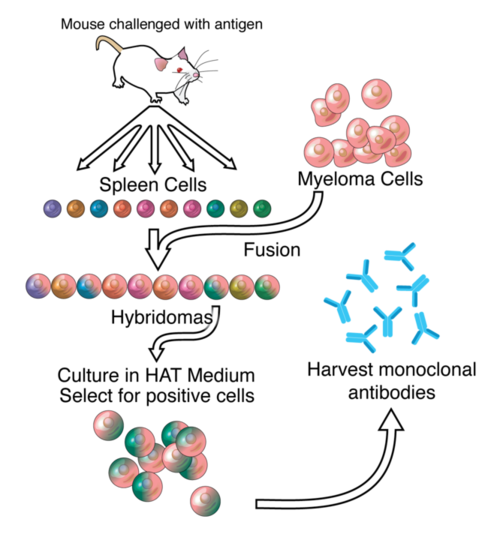
Let's say you want to create an therapeutic antibody against a protein.
Typically, you start by immunizing an animal with the protein (antigen) of interest,
and harvesting the antibodies that the animal creates in response.
Then you "humanize" the antibody (replace parts of animal IgG with human IgG)
and start testing in humans.
Although this method (and many permutations) has been working well for many years,
there are still unpredictable effects, and an antibody developed in this way
is far from assured to be safe and effective.
Recently, companies like X01
have shown the value of using "fully human" antibodies as therapies.
X01 started with an anti-thrombin antibody isolated from a patient with an unusual
clotting phenotype.
They turned this antibody into an anticoagulation therapy and sold it to J&J this year.
So to generalize, instead of immunizing an animal with your antigen,
you can try to find a human with the unusual phenotype you want and
develop an antibody that way.
The major putative advantage is that you start off with a free n-of-one human experiment
showing that your therapy is safe and effective.
The problem changes from one of biochemistry to bioprospecting.
PCSK9
Human genetics is playing an increasingly important role in drug development,
especially in helping determine the best drug targets.
The most famous example of this is the gene PCSK9, which, when homozygous null,
results in very low LDL, excellent cardiovascular health, and no apparent side-effects.
After its discovery, several pharma companies immediately began developing therapies
against this target.
This discovery also likely played a part in Amgen buying DeCode, Regeneron's huge
human genetics effort, and Robert Plenge
(@rplenge) joining Merck.
For an excellent summary of the PCSK9 story,
see this excellent talk by Jonathan Cohen.
Natural knockdowns
So we know that fully human antibodies have very attractive properties,
and we know that human genetics can help us find useful targets. Can we combine the two?
George Church sometimes shows a slide listing many of the known protective mutations.
These genes are mostly full knockouts (nulls)
and, perhaps surprisingly, these broken genes are sometimes beneficial.
Knockdowns are similar to knockouts, except here the protein is made correctly but
then suffocated by something else, like an antibody.
(Knockdowns normally refer to inhibition at the nucleotide level,
but the term seems to fit better than the alternatives.)
Natural knockdowns would present similarly to human knockouts, except that they
would not be present at birth, but would develop later in life.
In other words, these are unusual autoimmune diseases.
Myostatin
After going through various lists of beneficial knockouts, one stands out: myostatin.
Myostatin is an inhibitor of muscle growth, so the knockout results in a muscular phenotype.
There is at least one known
homozygous null human,
an extremely muscular German toddler.
In the animal kingdom, there are several examples, including the
Belgian Blue cow.
A natural knockdown of myostatin would theoretically result in unexpected muscle development,
perhaps late in life, and without a change in lifestyle.
A myostatin knockdown fulfills my criteria:
It is an extracellular protein
The protein must be accessible by antibodies.
It has an obvious therapeutic application
Myostatin antibodies are potentially a treatment for many muscle-wasting diseases.
There are already several in development by a number of companies
(e.g., Pfizer,
BMS).
It has a measurable phenotype
Greatly increased musculature is pretty easy to measure, perhaps even easier than LDL.
The phenotype is benign
This is not completely necessary, but it is an attractive property
in terms of safety that the antibody does not cause another disease.
Of course, it is not trivial to find a person with this unusual phenotype
— if they even exist —
but if we could, then they might by carrying an extremely useful therapy in their blood.
If you know someone who has added a lot of muscle quickly and cannot explain why, let me know!
Last week, Biogen released some Phase Ib data for their Alzheimer's
drug, Aducanumab (BIIB037). I don't know too much about how these
issuances work, but it's bizarre to me that you can show a chart at a
conference, and not the actual data, and yet the information increases
Biogen's value by billions of dollars. Maybe someone has access to the
raw data, but I can't find it --- that sounds illegal for a public
company anyway.
On Twitter, there was some skepticism about the data that piqued my
interest. Someone said they didn't trust the data because just a few
patients changing tack could change the results. It sounds plausible,
but it's not obvious how to quantify that. Others said the experiment
was underpowered; with about 20 patients per arm of the study, that also
sounds plausible.
I decided to take a look at the data to see if there is anything more
quantitative to say.
# This cell is just setupfrom__future__importdivision,print_functionfromIPython.displayimportImage,SVGimportnumpyasnpimportpandasaspdimportrandomfrompprintimportpprintfrommatplotlibimportpyplotaspltimportseabornassnssns.set_style("whitegrid")SVG_HEAD="""<?xml version="1.0" standalone="no"?><!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd">"""defuprint(astr):print("{}\n".format(astr)+"-"*len(astr))%matplotlibinline%configInlineBackend.figure_format='retina'
I thought the data from a slide on reduction in SUVR (a measure of
plaque volume in the brain) looked the meatiest. They also showed data
from MMSE and CDR-SB (paper-based tests), and a couple of other slides
on plaque volume. For my purposes, I think it's reasonable just to test
the assumption that the drug reduces plaque volume, not that it improves
cognition.
I used Photoshop's awesome perspective crop tool to correct for the
perspective on these charts. Then I used SVG to manually determine the
values in the chart. Not terribly sophisticated, but I think it works as
well as anything else out there; it's flexible and only a few lines of
code.
Now I can map these hand-drawn rectangles onto numbers, using the
transparent yellow box as a reference. Unfortunately, there is no data
for Week 54 / 6 mg/kg.
Based on these means and standard deviations, I can generate example
values, maximizing the entropy since I want these values to represent
only what I know from the chart. Here, this just means assuming a normal
distribution. In reality, it's unlikely to be normal, since there are
obviously important covariates like APOE e4 status.
Now that I have some values, I can run t-tests and see if my p-values
agree with the p-values in the chart. The chart only indicates whether
or not their statistical test produced p-values of less than 0.05 (*),
0.01 (**), or 0.001 (***).
The results generally agree pretty well with the chart. In fact, the
first time I ran this code, they agreed completely. Again, covariates
are bound to matter here.
At the bottom of the slide it explains that the data were analyzed with
an ANCOVA (like ANOVA with covariates). Each dose of the drug is also
compared pair-wise to the placebo to get a p-value per dose. The
statistical test they used to get their p-values is not mentioned, but
if were from a two-group ANCOVA, it should produce similar results to a
t-test.
The big caveats are that I don't have access to the listed covariates
and I don't know the true distribution of effect sizes.
fromscipy.statsimportttest_indfromitertoolsimportpermutationsdef_stars(pval):stars=[(.001,"***"),(.01,"**"),(.05,"*"),(np.inf,"")]returnnext(s[1]forsinstarsifpval<=s[0])uprint("Pairwise t-test p-values")forwkin[26,54]:uprint("Week {}".format(wk))fordose1,dose2in((a,b)fora,binpermutations([0,1,3,6,10],2)ifa<b):ifwk==54and6in(dose1,dose2):continue# no data for 54/6_pvals=[]for_inrange(100):v1,v2=e_vals[(wk,dose1)].next(),e_vals[(wk,dose2)].next()_pvals.append(ttest_ind(v1,v2)[1])pval=np.mean(_pvals)# arithmetic meanprint("{} vs {}\t{:.4f}\t{}".format(dose1,dose2,pval,_stars(pval)))
Pairwise t-test p-values
------------------------
Week 26
-------
0 vs 1 0.3751
0 vs 3 0.0497 *
0 vs 6 0.0022 **
0 vs 10 0.0000 ***
1 vs 3 0.1364
1 vs 6 0.0132 *
1 vs 10 0.0000 ***
3 vs 6 0.1619
3 vs 10 0.0032 **
6 vs 10 0.1066
Week 54
-------
0 vs 1 0.1441
0 vs 3 0.0013 **
0 vs 10 0.0000 ***
1 vs 3 0.0411 *
1 vs 10 0.0000 ***
3 vs 10 0.0087 **
Robustness
How sensitive are these results to changes in the data? It's not obvious
to me what the best way to test this is, especially without the real
data. One simple way to test robustness is by zeroing some fraction of
the data. In other words, for some fraction of patients, make it so that
the drug has zero effect.
Here, I artificially zero from 0 to 100% of the plaque volume values,
and plot the p-values for each dose.
The results graph shows that you would need to zero out about 20-40% of
the data for the results to move down a p-value category (e.g., from
0.01 to 0.05).
Another way to think about that is you would have to have 4-10 patients
in an arm of the study who, instead of responding, did not respond at
all.
While that doesn't seem implausible, if it happened, only one of the
five significant p-values in the graph would be affected. Hence, I think
the results as presented are pretty robust to patients switching to
non-responders.
Power and priors
Is the study underpowered? Since it's a phase Ib, it's almost by
definition underpowered to detect treatment effects. However, it also
depends a lot on your prior for an Alzheimer's drug working. If these
data were not for Alzheimer's, but something more innocuous, it might
not be called underpowered.
The prior could include the general lack of success of Alzheimer's
drugs, but also intangibles such as potential data-dredging, unconscious
biases, generally bad science (see Ioannidis), the huge amount of money
at stake, and maybe (as someone suggested) even the age of the CEO.
Obviously, I have no idea. The stock is already up about 30% since
January though (when preliminary data appeared) and about 10% this week,
so maybe only if you think the probability of approval is well above
35%.
This twitter conversation is a nice microcosm of what's going on in drug discovery.
On the human genetics side, we have Robert Plenge, Daniel MacArthur, Amgen and Regeneron,
who believe sequencing humans will be the key to better drugs (a la PCSK9).
On the model organism side, we have Ethan Perlstein
(and certainly others, perhaps Roger Perlmutter from Merck?),
who think that the human sequencing stuff is overblown.
In the end, there's not too much disagreement:
humans are good for target discovery,
model organisms can be useful models of those targets.