This is a simple experiment in simulating evolution and predator–prey dynamics, where the predators and prey have simple brains that learn to sense their environment.
Click here to start the simulation.
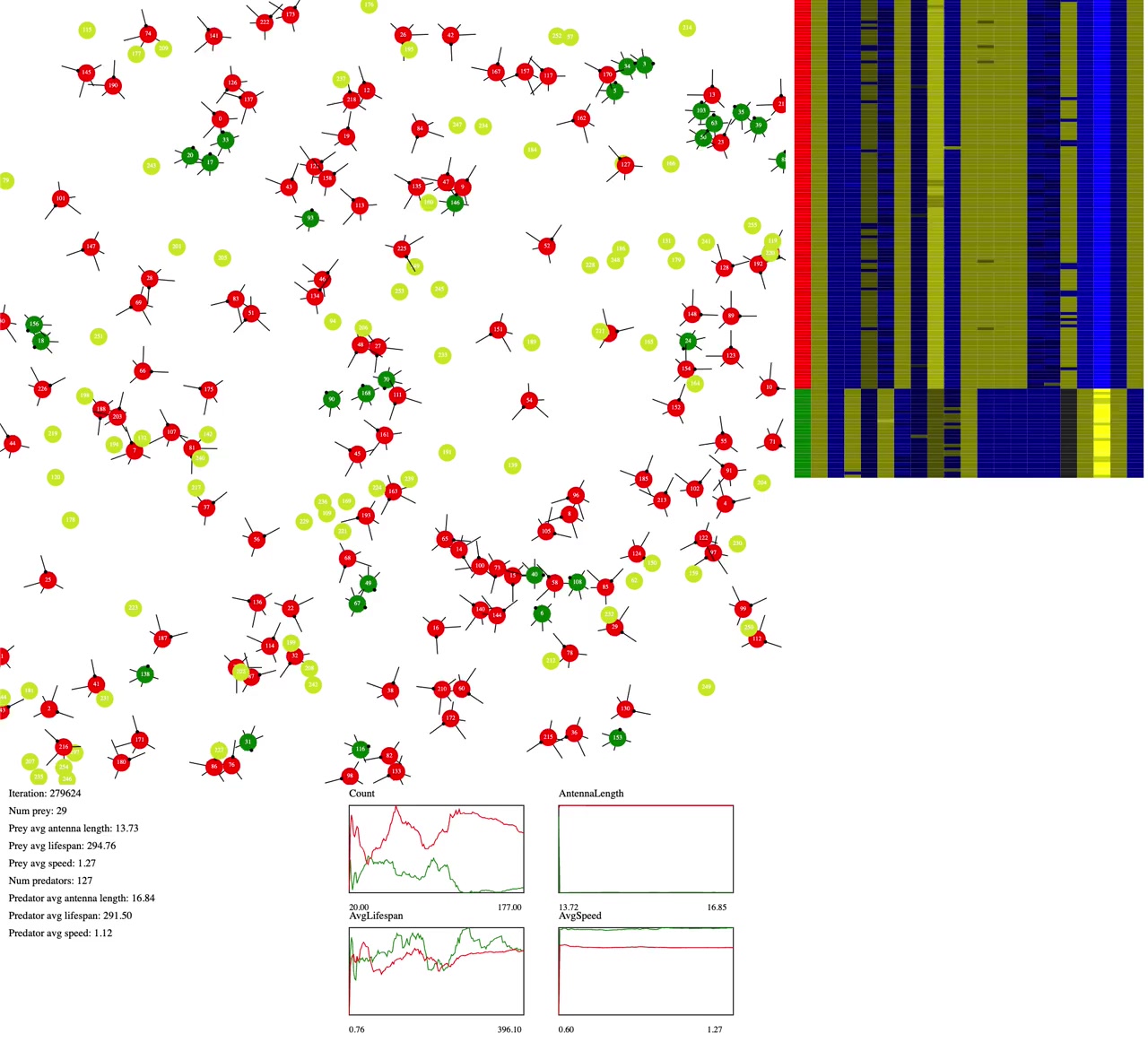
The setup
There are three types in the simulation: one static type (food, light green), and two microbes that can evolve (predators, red, and prey, green).
Food appears spontaneously (via photosynthesis?); prey eat food, creating progeny prey; predators eat prey, creating progeny predators.
When microbes go off the top, bottom or sides of the screen, they loop around, like Pac-Man. Interestingly, this means their world is a torus!
Evolution
Every generation, the predators and prey have a few parameters that change a bit, according to the mutation rate:
- 1 speed parameter: generally, faster leads to greater fitness
- 8 antenna length parameters: generally, longer antennae lead to greater fitness
- 20 neural network parameters: these are connected to their antennae and dictate their actions
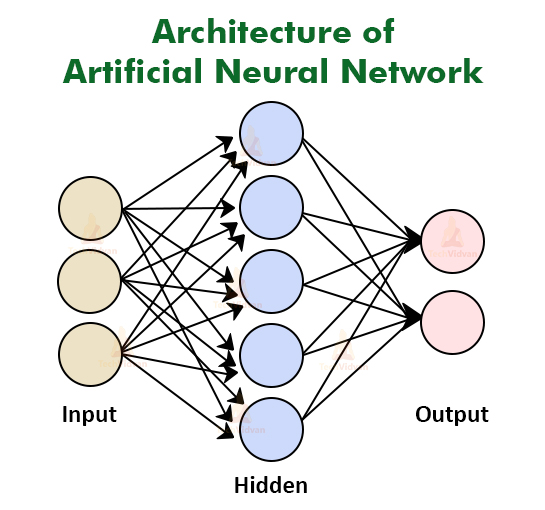
Neural network
Predators and prey each have 8 equally spaced antennae that act as sensors. Each of the 8 antennae can sense 4 things: Empty, Food, Prey, Predator. So the input matrix to the neural network is a simple 8x4 one-hot matrix.
The final output I want is a length 2 vector representing a decision for the microbe's next direction and speed.
The simplest way to convert an 8x4 matrix to a 2x1 vector is to multiply by an 8x2 matrix, to make a 4x2 matrix, then multiply by a 4x1 matrix to make a 2x1 matrix. Hence, there are 16 + 4 total weights to learn.
This creates a feedforward neural network with one hidden layer, but even simpler than most because there is no thresholding or activation function. For this application, it just seemed to work better to allow the microbes to learn their speed and direction values directly, and cap their speed after the fact if necessary.
Balance
I have played a little with simulations like this before, and it's surprisingly difficult to keep things balanced. A minuscule advantage can snowball and lead to an extinction event almost immediately.
The main thing keeping this simulation balanced is that there is a fixed maximum of 256 objects (food, prey, predators) at any time. I mainly did this because it fits well with numpy code and is fast, but it turns out to really help with keeping the simulation in equipoise.
I also set "endless mode" by default, which stops predators and prey dying if it looks like they are going extinct.
As the predators and prey speed up, the swings in their population sizes become greater, and you either see the expected predator–prey to and fro or eventually the predators and prey become too fast for the world size, and this seems to keep the prey at a low population size.
What do they learn?
Looking at the little guys, it's natural to ascribe agency to their actions and overinterpret, so with that caveat, the prey do seem to consistently learn a few things.
- They learn to use their front antennae to brake when they touch predators (change speed)
- They learn to use their left and right antennae to swerve predators (change direction)
- They learn to keep their front antennae long and may or may not lose their back antennae
They predators appear to learn much less. They can thrive if they go fast, so in general they speed up, but their brains don't seem to help them much at all!
Anecdotally, prey brains and predator neuron weights look different, but I haven't really checked how consistent these differences are yet.
After ~100,000 iterations, prey learn to swerve and brake
Claude
The original code was some numpy-heavy Python, but I decided to see if Claude 3.5 could translate that to JS/HTML. Overall it worked very well and saved a bunch of time, but parts of the process were still painful. I got best results when I asked it to transliterate Python line by line. For adding HTML stuff like the graphs, it worked better. The simulation is relatively slow to run and could be sped up a lot at the cost of some complexity.
The code is quite simple (github),
but the simulation has enough emergent behavior that it is pretty mesmerizing to watch.
Top left: the main play area; Bottom left: data and graphs; Right: neural network data with one row per microbe and 20 columns representing neuron weights